供應鏈的需求預測,一直以來都是企業營運的重要議題。這是個不需要多加贅述的事實,相關的參考資源與文獻也不勝枚舉。而提到需求預測,不外乎直觀地聯想到使用過去的資料來預測未來的結果。而若這些資料正好也具有時間相依性,那就是時間序列預測模型能派上用場的時候,這也是筆者將這篇文章歸納在「時間序列」這個大類別的主要原因。
然而,但就跟當前的人工智慧應用落地的困境一樣,現實情境當中的需求預測,往往不可能只靠一個好棒棒的時間序列模型,就能產出可用的預測結果。而本文的重點,也不是要把那些翻翻教科書、或者網路上Google就能找得到的玩意再談論一遍,而是要分享筆者於業界實際從事供應鏈需求預測建模的相關經驗。
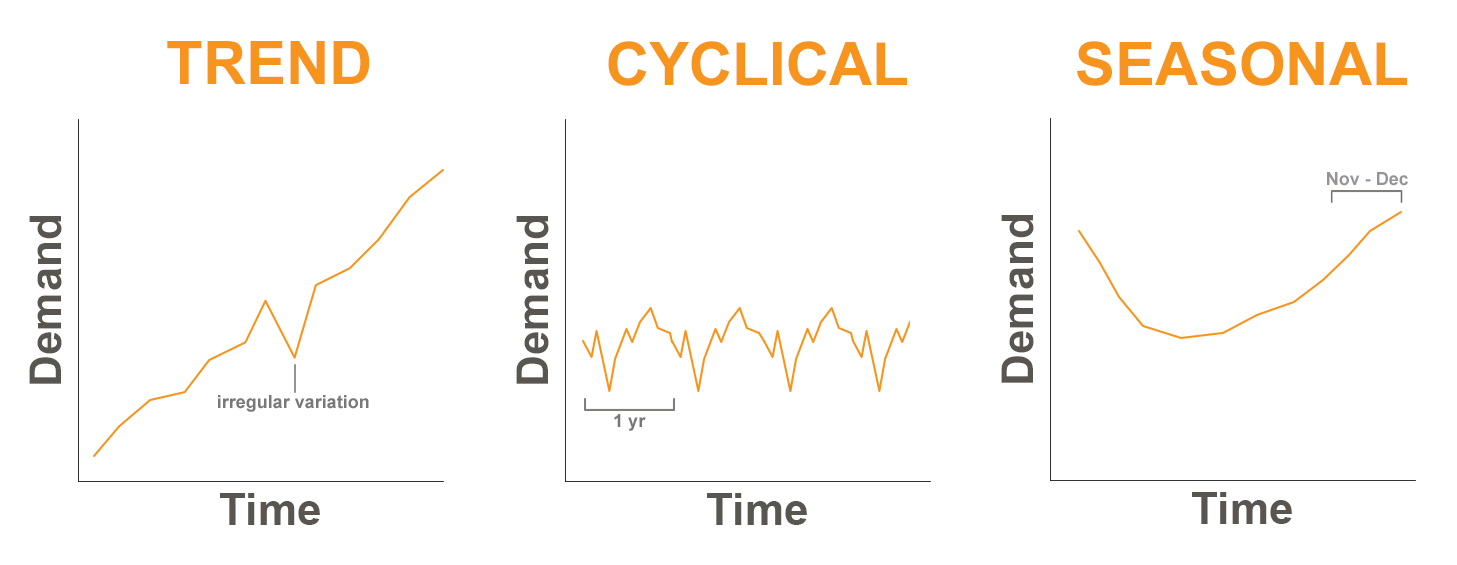
# 時間序列成份解構
先不考慮其他影響因素,針對歷史資料進行詳細地剖析,都是需求預測的第一步。而對於時間序列的資料,最常見且直觀的剖析方式,就是將其進行成分拆解。傳統的時間序列解構,大抵上可分為趨勢項、週期項、與殘差項這三類。一些較新穎的時間序列預測模型,還能夠針對同一條序列資料,拆解出不同頻率的季節或週期項的成份;或者是針對殘差項再進一步拆分成事件項的成份,但我們一步步來談。
- 可任意設定週期項的頻率與發生時間點。
- 拆解出來的趨勢項能夠完整保留原始序列資料的長度,而不會因為平滑的區間拉長而使拆解出來的趨勢項資料短少。
- 能根據使用者的設定,使拆分結果較不受離群值資料的影響。
而針對季節週期因子的拆分,除了上述單純拆解時間序列的方法之外,近幾年一些屬於加法模型(Generalized Additive Model)的熱門時間序列預測演算法套件如:Facebook 的 Prophet 、LinkedIn 的 Silverkite、Uber 的 Orbit,本身也能透過模型配適,針對歷史資料以及預測值進行拆解。此外,這些整合性的預測模型套件,通常都具備自動偵測週期特徵的功能,使用者可以很無腦的使用「全自動模式」,讓模型從資料當中抓出具備哪些週期特徵。只是,我們手頭上的資料,真的具有我們以為的那些季節或者週期特徵的意義嗎?還是說只是剛好看起來很像?
# 拆解週期項的陷阱
無論是 STL 或者傳統的時間序列拆解方法,都是假設使用者已知歷史資料具備哪些季節或者週期特性。也就是,當我們在使用這些方法拆解歷史序列資料時,我們得人為去設定季節與週期的頻率,以及計算趨勢項的平滑區間。
例如:許多新手資料科學從業人員在進行時間序列的資料分析與預測建模最常犯的錯誤之一,就是直接把自己需要產出分析報表或者產出預測結果的週期長短,直接套用到所要分析的資料上。如果只是產出樞紐分析報表,可能還好。但是以這種方式來設定時間序列的拆分週期,那就很有問題,因為實際上的資料可能根本不具備那樣的季節或者週期特性的意涵在。即便是上述那些能夠自動偵測週期特徵的時間序列預測模型套件,其所偵測出來的週期特徵,也不見得就真的具備實際上的季節與週期性意義。
原始資料的季節與週期項意涵,必須與領域知識與實際業務情況結合,才能夠產生意義。否則,若貿然使用這些「看起來很像」的季節週期拆分結果來做進一步的預測建模應用,除了可能造成預測成效不如預期,產生出來的預測結果也無法貼近實際的業務應用場景。
# 從資料尋找週期
現在,我們知道該好好的審視季節與週期的長度設定了,但是,除了結合業務面來瞭解與確認資料當中的週期特性之外,有沒有能夠直接從資料本身來判定週期時間長短的方法?當然有。這種時候可以,使用統計學的 ACF 和 PACF 檢定,即「自相關函數」( Autocorrelation Function,ACF ) 與「偏自相關函數」( Partial Autocorrelation Function,PACF ),並搭配 AICC、BIC、HQC 等資訊量準則,來判定原始資料當中是否具備較顯著的週期特徵。
ACF 和 PACF 檢定並非只能用於檢定原始資料是否為平穩序列,根據所設定的週期長度 ( Lags ) 不同,其也能應用於不同週期頻率的檢定。而 AICC、BIC、HQIC 等資訊量準則,則是根據不同的考量面向,來判定一個統計學模型好壞的評估指標。由於這些檢定方法以及資訊量準則並非本文的重點。讀者們可以參考下方連結、或者根據關鍵字來自行搜尋相關資訊。回到本文核心,這裡還是要強調,透過這種方式找出來的週期長度,仍必須與領域知識與實際業務情況結合,才有意義。
# 供應鏈最末端的需求週期特性
談了一堆時間序列的理論方法之後,我們接著來看本系列的另一大重點:供應鏈的需求預測。首先我們應當都能夠同意:不同產業、不同類型的產品或服務、以及公司本身處在供應鏈上下游當中的哪個位置,其對應的需求預測方法,都會不同。作為本系列的第一篇文章,我們就先從生活當中常見的餐飲門市、食品與民生用品零售的超商、超市、與量販店談起。
站在門市的角度而言,通常不太需要什麼太複雜的需求預測模型。因為零售終端的商品及服務往往是屬於推式需求,這類需求的整體變動幅度通常不大、且通常不需要考慮產品生命週期的問題。而門市的日常作業原本就十分繁重,通常會採用所謂的「安全庫存水準 」的這一類的管理方法。也因為採行這種存貨管理方法的緣故,相較於「準確的需求預測」,「不缺貨」、以及「充足的現場人力」通常才是門市的營運重點。即便需要進行需求預測,也不會是 by 個別商品或服務來進行預測,而是 by 某個大類別的需求、以及每日的營業情況來調整其採購與銷售計畫。類似情況也發生在購物網站的食品與民生用品的需求預測上。只不過,實體門市可能只需要顧及到商品圈 內的即時需求變動就行了。購物網站要面對的可能就是全國、乃至於海外的客戶需求。
而在這裡優先提到零售門市的原因是,這類位處供應鏈最末端的產品與服務、由於較容易與消費者的日常生活息息有緊密關聯,通常是最能直接反映出季節與週期特性影響的需求類型。除此之外,正如上述所提到的,這個環節的供應鏈需求預測,往往都是 by 一個商品的大類別、甚至是一整間門市的整體需求預測。個別商品的需求變動的隨機性誤差,通常在往上彙總計算的時候被稀釋掉了,而使的整體的季節與週期更容易被彰顯出來。這也是當我們看到一些門市經理、或者是區督導,在進行需求預測時,會比較看重季節週期影響的原因。但若今天談的不是餐飲或者民生用品,而是電子產品,且可能還不是一般民用的 3C 產品,而是工業用的電子產品或者重要零組件時,那麼就又是另外一回事了。這個部份,我們就留待後續的文章再討論。
# 零售終端的需求預測現實
這裡還可以再多分享的一點是,由於門市的管理者在進行需求預測時,大抵脫離不了上述的策略範疇。若是屬於連鎖加盟體系的門市,那麼需求預測的工作可能還再往上一層的區督導來負責規劃,而相較於精準的需求預測,管理者可能更傾向將工作重心放在廣告行銷與活動企畫上。
畢竟,對於門市而言,精準的預測最多就是降低庫存成本、增加採購彈性。尤其實際有實際業界經驗的我們一定曉得,這種預測數量的玩意要面臨的不確定性因素實在太多了,即便是用個複雜的預測模型都很難準到哪裡去了,更別提提門市或者區督導的管理人員,本身也不見對預測性計量方法有多深的瞭解。再加上時間有限,很可能就是一個簡單的線性迴歸、或者指數平滑法抓出個 baseline 之後,再依照管理經驗、結合未來較明確的季節與節慶事件因素,就生出一個預測結果來湊合著用。這樣的需求預測結果,重點就真只是做為基準線來參考。而不是要力求預測的精準。
反觀,若是行銷與活動企劃湊效,那通常能夠直接反應在公司的營收上。這也是為什麼,雖然需求預測是公司營運的重要議題,但是大多數的公司經營者卻不見得重視到哪裡去的原因。正是因為預測模型很難做到準,所以不如把資源投注在其他比較能夠立即見效的政策活動上。不然我們也不會有機會到現在還看到各大科技巨擎的研發團隊、或者世界知名大學,不斷提出新的數量預測方法了。