本系列的前五篇文章談到的,幾乎都是單一變數的時間序列資料。也就是假設每一樣產品的需求為獨立,彼此互不影響,每一項產品的預期需求完全分開來預測。但在業界實務當中,我們手頭上的時間序列資料,可能有群組與階層的隸屬關聯,而本系列的最後一篇文章,就是要聊聊具有這種結構關係的需求預測難題。
# 簡單的群組與階層拆分與整併預測
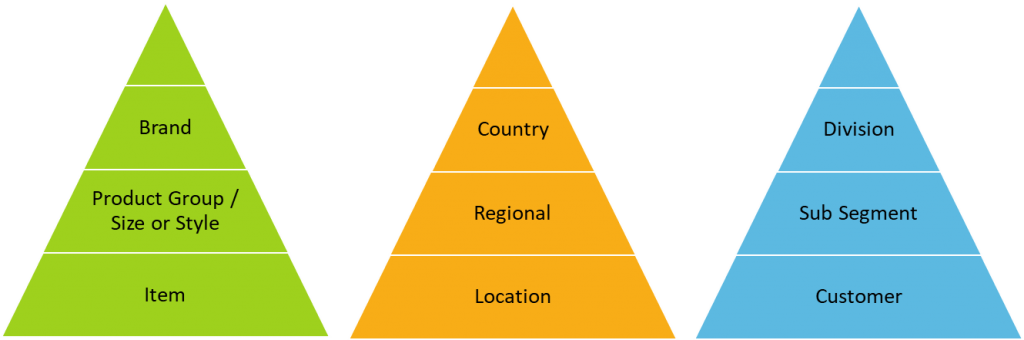
以筆記型電腦為例,假設某品牌商旗下有兩個不同系列的筆記型電腦(姑且就稱為 A 款與 B 款),假設這兩款都可以依照螢幕尺寸再分成 14 吋與 15 吋好了,該品牌的 A 與 B 兩款筆電都銷售全球(就粗略分成亞太、北美洲、歐洲、與新興市場四大地區好了)。有了上述的類別標籤,我們就能依照這些標籤,將過往的銷售數據進行群組與階層的拆分或整併。而在進行需求預測時,無論我們是「由下而上」(Button-up)先將切到最細層級的個別序列資料(例如 A 款的 14 吋筆電在亞太地區的未來預期需求)分別預測之後,再逐層往上堆疊;抑或是「由上而下」(Top-down)先使用彙總到最頂層的序列資料進行預測之後,再依照特定比例拆分到底下各層,這種兩分預測流程,從技術面而言都說得通,相關細節可以參考該電子書的章節頁面 ,裡頭有十分詳盡的觀念談。
# 同時預測多條時間序列
若我們採行的是「由下而上」的預測方式,且假設我們明確知道同階層或同群組的序列資料當中,彼此具有一定程度的關聯性存在。這種時候就可以使用向量自迴歸模型 (Vector Autoregression),針對同一階層或者同一群組的時間序列資料來進行預測。然而,就跟其他基於統計學的時間序列預測模型一樣,該方法的使用上要留意一些的限制與假設前提,否則用起來的預測成效也不會好到哪裡去,甚至根本用不起來。例如最簡單的:當你一次把太多條時間序列綁成一個龐大的矩陣來求解……那麼求解的複雜度指數上升,甚至模型會因為無法收斂而直接跳 Error 給你看。又或者是,你綁在一起預測的這些時間序列壓根沒有統計上的關聯性,那麼為了圖方便性而向量自迴歸模型來做預測的結果,就跟你拿一串隨機序列的資料說要用 ARIMA 模型來準確預測下一步,是一樣的概念。
# 群組與階層的陷阱
延續上個段落所提到的,既然都特地寫了這篇文章,當然不是請讀者們把上面那本電子書的章節看過而已。雖然在業界當中的許多產品需求資料,都能夠依照上述方式來進行群組與階層的拆分與整併,但若要將相同群組或階層之間的序列資料綁在一起預測的話,那麼最基本要確認的這堆相同群組或者相同階層的時間序列資料,究竟有沒有關聯性?或者是確認其不同序列的殘差之間是否為獨立?
但很多時候,這些群組與階層的類別標籤,其實只是相關單位便於分類與統計分析而加上去的人為定義料罷了,實際上這些相同群組或者相同階層的時間序列,彼此可能根本沒有關連性存在。就好比本系列的第一篇文章所提到的一樣,人們經常會用慣用的時間顆粒度單位,例如:每週、每月、每季等等時間區間來彙總資料,但是在需求預測建模的時候,依照這些區間來劃分的時間序列,不見得就能帶來良好的預測成效,或者資料本身不具備那樣的季節或週期特性。這也是新手資料分析師、資料科學家在使用群組與階層的預測方法來進行預測的,經常落入的陷阱。
所以至少最基本的,從資料面的角度來看,我們可以用 Granger’s Causality 檢定方法來確認相同群組或者相同階層的時間序列資料彼此是否具備關聯性。以及可以用 Durbin Watson 檢定方法來確認不同序列的殘差之間是否為獨立。而就算它們之間真的存在關聯性,其關聯性可能具有滯後(Lagged)的性質,白話來講,可以理解成 A 時間序列在 t 時間點的急漲,可能與 B 時間序列在 t+1 時間點的急跌有很大的關聯。這種時候,就可以考慮使用「滯後預測模型 」(Lagged Predictors),例如:「自迴歸分佈滯後模型」 (Autoregressive Distributed Lag Model,ARDL)或者其他的考量了分佈滯後(Distributed Lag)假設的模型。
# 新潮的時間序列預測方法
截至目前為止,本系列文章所提到的時間序列預測方法,大抵上都基於統計學的時間序列預測方法。或者是在前三篇文當中,筆者不只一次提到了如 Prophet 、Silverkite 、Orbit 等基於加法模型(Generalized Additive Model)的熱門時間序列預測演算法,那是因為,本系列文章開宗明義就是在講供應鏈的需求預測實務。如何透過一些 rule-based 或者基礎的計量方法,將實務場景當中的業務邏輯化作模型的一部份,才是筆者所比關注的。因此,越是簡單、可解釋性越高、可掌握性越高的方法,通常在應用上的彈性也越高。尤其是對於工廠單位的產銷需求預測而言,更是如此。這也是為什麼,時至今日,那些基於統計學的經典時間序列預測方法(如移動平均模型、自迴歸模型、ARIMA、ETS)到現在仍被作為許多複合型預測系統的基礎模型,或者至少會被拿來當做事 baseline 的原因。而之所以一再提到加法模型,就是因為這些複合型的方法,能夠進一步拆分成各個不同功能的子函數,使用者可以再依照本身的需求來組合與調整運用,因此使用上也比較符合上述的任務需求。
但這不代表所有供應鏈環節上的需求預測任務,都這麼注重這些要點。例如供應鏈最末端的零售門市、或者電子商務平台。由於終端消費者本身的需求行為就受到太多難以追蹤、或難以求證求證的不確定因素影響。這種時候,一些基於機率、或者隨機演算法的新潮預測模型,就有機會派上管用。而既然本文提到了階層預測與群組預測,那當然一定要來介紹一下「DeepAR」 這款基於人工神經網路的強大時間序列演算法。其主打四大特色 :
- 「支援機率預測」(即不像傳統的 ARIMA 或者 ETS 模型那樣,只能產生單一個點的預測值,而是根據模型配適結果,以及設定的信心水準範圍,回傳一個預測值的機率分佈區間);
- 支援多變數的預測結構(即除了使用單一時間序列的歷史資料來訓練模型之外,也支援多元迴歸形式的預測建模);
- 能夠支援一次性的群組與階層時間序列資料的訓練與預測(這個就真的強大了);
- 宣稱對於單期以上的預測任務也能保有強健的準確度
(實際上到未來多少期還能預測得準,這裡就不好說了)。
當然,在這個號稱人工神經網路的產物漫天飛的年代,像DeepAR 這種炫砲的預測模型當然還有很多。而撇開預測成效不談,這種基於機器學習或者深度學習的預測演算法,通常有一堆參數需要調校,以及訓練模型跟產生預測結果的過程,都會比傳統上基於統計學方法的時間序列預測模型要耗時。即便是使用了如 GCP、AWS、Azure 等知名科技大廠的整合雲端運算服務,所需要的模型訓練與預測的時間成本仍舊十分可觀。
除了模型訓練、參數調校之外。這類基於機器學習或者深度學習的預測演算法,要是沒有足夠的訓練資料,那麼也只是好看的裝飾品,發揮不了真正的強大效能。這些都是如果真要使用這些炫泡演算法以及整合運算服務來進行企業級的需求預測任務時,該特別留意的點!而由於這類方法並非本文所要討論的重點,故我們就點到為止,讀者們透過關鍵字便能找到非常多的工具與參考資源。
# 尾聲
本系列的六篇文章當中,筆者蜻蜓點水地帶過許多時間序列預測的方法與觀念,同時在每一篇文章當中都提到了一些在業界當中進行需求預測時的實務要點。某些資料科學工作者可能會認為這些內容太過於簡單且理所當然。但事實上,許多的藏在細節當中的魔鬼,正是因為我們太過理所當然如此這般地認為,才錯過了能夠把魔鬼抓出來的機會。而這六篇文章,不僅是筆者自己的職人心得筆記,同時也是筆者在資料科學匠人之路上不斷成長的基石!